¿Cómo entender las colecciones de patrimonio cultural como materiales que pueden investigarse con métodos computacionales? Esta fue una de las preguntas que guiaron el Collections as Data Jam, organizado por un grupo de desarrolladores y bibliotecarios de Humanidades Digitales, en el marco de la primera conferencia ACH2019 de la Association for Computers and the Humanities, una asociación profesional para las humanidades digitales en los Estados Unidos, que se llevó a cabo entre el 23 y el 26 de julio en la ciudad de Pittsburgh.
Con el acceso cada vez mayor a objetos culturales digitalizados, uno de los asuntos que ponen (o deberían poner) a conversar a bibliotecarios, archivistas y humanistas es cómo presentar las colecciones de objetos digitalizados (documentos, imágenes, etc.) como datos que se pueden manipular, analizar y visualizar con métodos computacionales. Esto significa pensar qué ha cambiado hoy con el acceso a millones de elementos culturales digitalizados tanto para la labor de quienes trabajan en instituciones de la memoria como para los humanistas quienes investigan estos objetos del pasado.
La digitalización de la cultura y su presentación en archivos digitales ha abierto miles de colecciones históricas, literarias, documentales, arqueológicas y artísticas, entre otras, para que investigadores y personas del común accedan a ellas digitalmente. No accedemos propiamente a los objetos sino más bien a representaciones digitales de obras de arte, periódicos, cartas, por mencionar algunos de ellos. Además de tener acceso a la representación, los archivos digitales nos permiten acceder a los metadatos de los objetos para analizarlos. El concepto de metadatos, que es bien conocido en el mundo de las ciencias de la información, es central para las humanidades digitales. Se trata de datos sobre datos, es decir, el objeto cultural tiene una serie de descriptores que suministran información ampliada y contextualizada del objeto. Por ejemplo, su fecha y lugar de producción y el autor del objeto (si se conoce), por mencionar algunos ejemplos básicos.
Durante el taller Collections as Data Jam, con el grupo con el que colaboré hicimos un ejercicio con las colecciones digitales de la Library of Congress, en particular con Chronicling America, un repositorio con periódicos de Estados Unidos fechados entre 1789 y 1963. Nos concentramos en buscar periódicos en español publicados en Estados Unidos desde comienzos del siglo XIX.
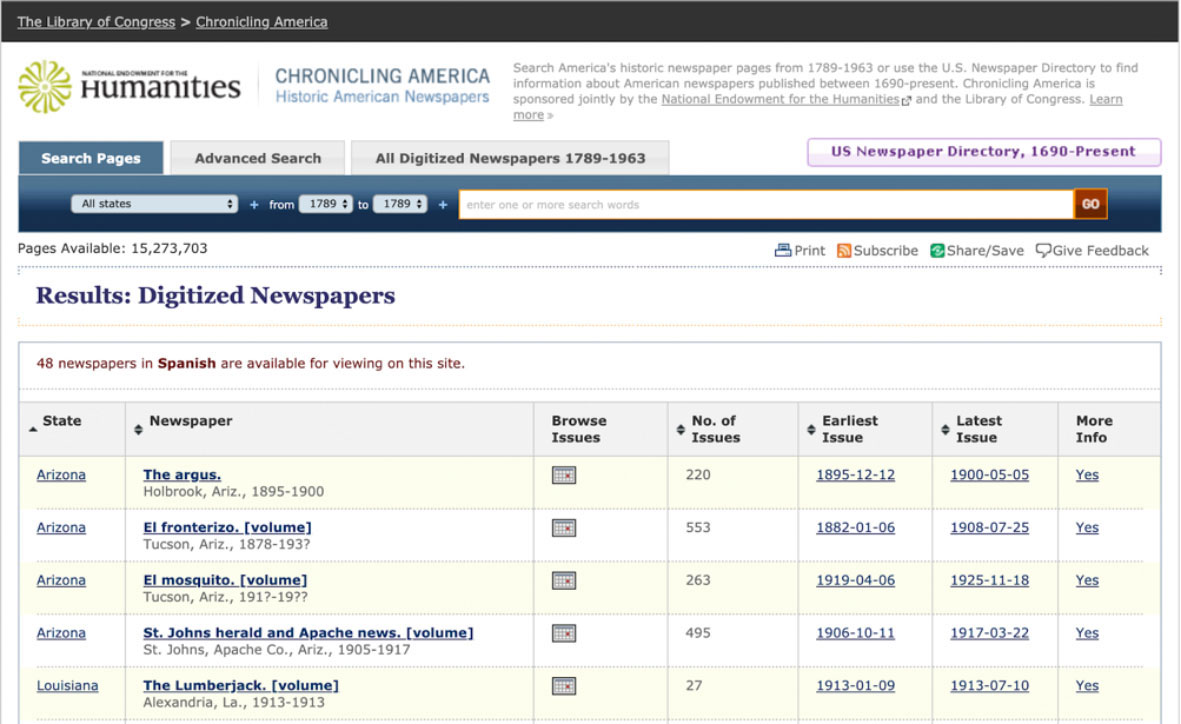
Sitio de Chronicling America, búsqueda por periódicos digitalizados en español
El conjunto de periódicos digitalizados de Chronicling America es uno de los repositorios digitales de la Biblioteca del Congreso que fue diseñado para permitir que los usuarios utilicen sus datos de varias formas. Por ejemplo, los protocolos web del repositorio no restringen la descarga de los datos de la colección y con la API (Interfaz de Programación de Aplicaciones) se puede acceder y explorar los datos. El repositorio incluye documentación sobre cómo utilizar la API, no solamente para hacer búsquedas sino también para probar técnicas de indexación del contenido de periódicos que han pasado por un proceso de reconocimiento óptico de caracteres (OCR).
En este ejercicio, descargamos los registros de periódicos publicados en español en Estados Unidos y los organizamos en una hoja de cálculo. Los campos que utilizamos para organizar los datos fueron: nombre del periódico, lugar de publicación, año de la primera edición y año de la última edición. Además le añadimos a la tabla de datos latitud y longitud para poder visualizar esta información en un mapa. El resultado del ejercicio de visualización con Time Mapper, una herramienta open source para crear líneas de tiempo conectadas a mapas, se puede ver acá. Por el volumen de la información contenida, Time Mapper no es quizás la plataforma ideal para visualizar estos datos, pero fue la que utilizamos para el ejercicio.
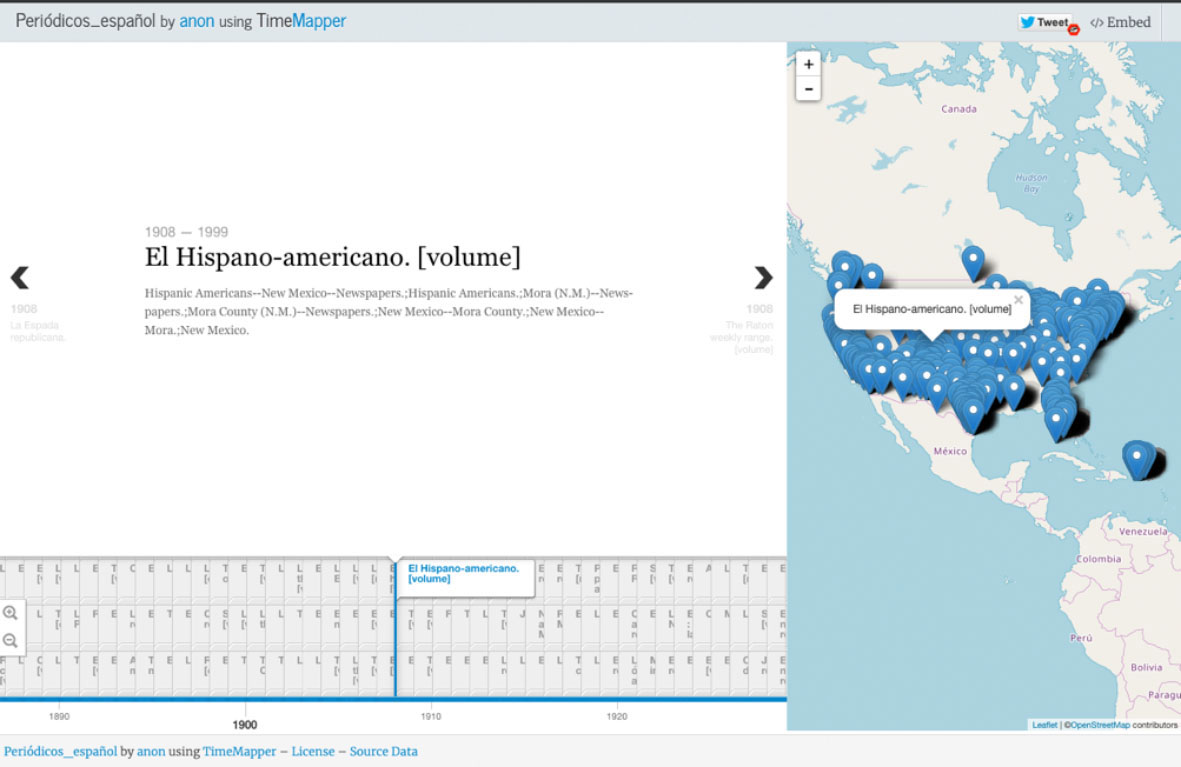
Visualización de la colección de periódicos en español en TimeMapper
En el proceso nos dimos cuenta que aun cuando los repositorios digitales permitan la descarga de datos sobre sus colecciones, siempre es necesario hacer un proceso de revisión y limpieza de datos. En este caso, muchos registros no incluyen la fecha inicial de publicación del periódico; la descripción de los temas de los periódicos incluían nomenclaturas que no eran útiles para los objetivos de la visualización; y algunos datos de georreferenciación contenían errores. Para limpiar datos se puede trabajar con OpenRefine. Una vez corregidos los datos, la visualización de la colección de periódicos permite navegar el archivo de formas que en físico sería imposible. Por ejemplo, en la visualización se podrían identificar patrones en la publicación de periódicos en español en Estados Unidos a través del tiempo. Este ejercicio de visualización de una colección de fuentes a partir de sus datos puede apoyar el proceso de formulación de nuevas preguntas de investigación sobre el pasado. El potencial de trabajo colaborativo en el marco de las humanidades digitales puede además ayudar a enriquecer los metadatos de las colecciones con categorías temáticas y/o conceptuales. Esto permitiría expandir las posibilidades de búsqueda y de interrogar conjuntos documentales extensos, es decir, acceder al récord cultural de la humanidades de formas antes impensables.
La idea de crear datos accionables con computadores puede conectar el trabajo de bibliotecarios, archivistas y humanistas para el desarrollo de colecciones digitales pensadas no solamente para fines de preservación. Este un debate para propiciar al interior de las instituciones de la memoria y universidades de cara a los retos de la digitalización de la cultura en un país como Colombia que, a diferencia de países del llamado Norte Global, enfrenta grandes retos en la gestión de archivos históricos. En un país con recursos limitados para proyectos de digitalización deberíamos preguntarnos para qué y para quién digitalizamos. Además de la preservación, pensar en las colecciones como datos puede ser un camino para añadir valor a los objetos culturales para la investigación, la pedagogía, la apropiación del patrimonio cultural y las causas de justicia social.
Algunos ejemplos de colecciones como datos y visualizaciones compartidos durante el Collections as Data Jam:
-Colores de la Biblioteca del Congreso. Experimento de LC Labs que muestra imágenes de las colecciones de la biblioteca como muestras de colores. Este experimento se ha llevado a cabo en diferentes colecciones, desde tarjetas de béisbol hasta estampas japonesas. Estos colores se extrajeron mediante el uso del formato de la API JSON de loc.gov. El código y la metodología de este experimento también se comparten a través de esta entrada de blog.
-
Visualizador de Dibujos Políticos. Proyecto curado por el LC Labs que consiste en una línea de tiempo que identifica los dibujos políticos relevantes de cada año. Esto permite que los dibujos reciban diferentes etiquetas para que los usuarios puedan buscarlos fácilmente.
-
Conjuntos de datos de archivos web. Los conjuntos de datos de archivos web de LC Labs son un conjunto de archivos web en categorías que van desde conjuntos de datos.gov hasta metadatos de Meme Generator. El propósito de este conjunto de datos es encontrar métodos para que la biblioteca organice mejor las masas de datos que la web tiene para ofrecer a través de estos diversos conjuntos de datos derivados.
Otro ejemplo de cómo trabajar con datos de colecciones grandes de fuentes primarias digitalizadas está en este tutorial de The Programming Historian en español Minería de datos en las colecciones del Internet Archive.
—Por María José Afanador-Llach
— Sitio web: http://mariajoseafanador.com/ — twitter: @mariajoafana